
“Most of the words you’ve ever read were written by a human, but that could soon change.”
That was how I began an essay almost exactly five years ago, which I titled “The internet is not ready for the flood of AI-generated text.” I wrote it after the first few months of GPT-3 (before “AI” was cool) and believe that the main thesis has held up pretty well through all of the hype and reality that followed. The systems that shape information environments care more about wringing every last ounce of engagement than about people or their best interests, and many have been overrun.
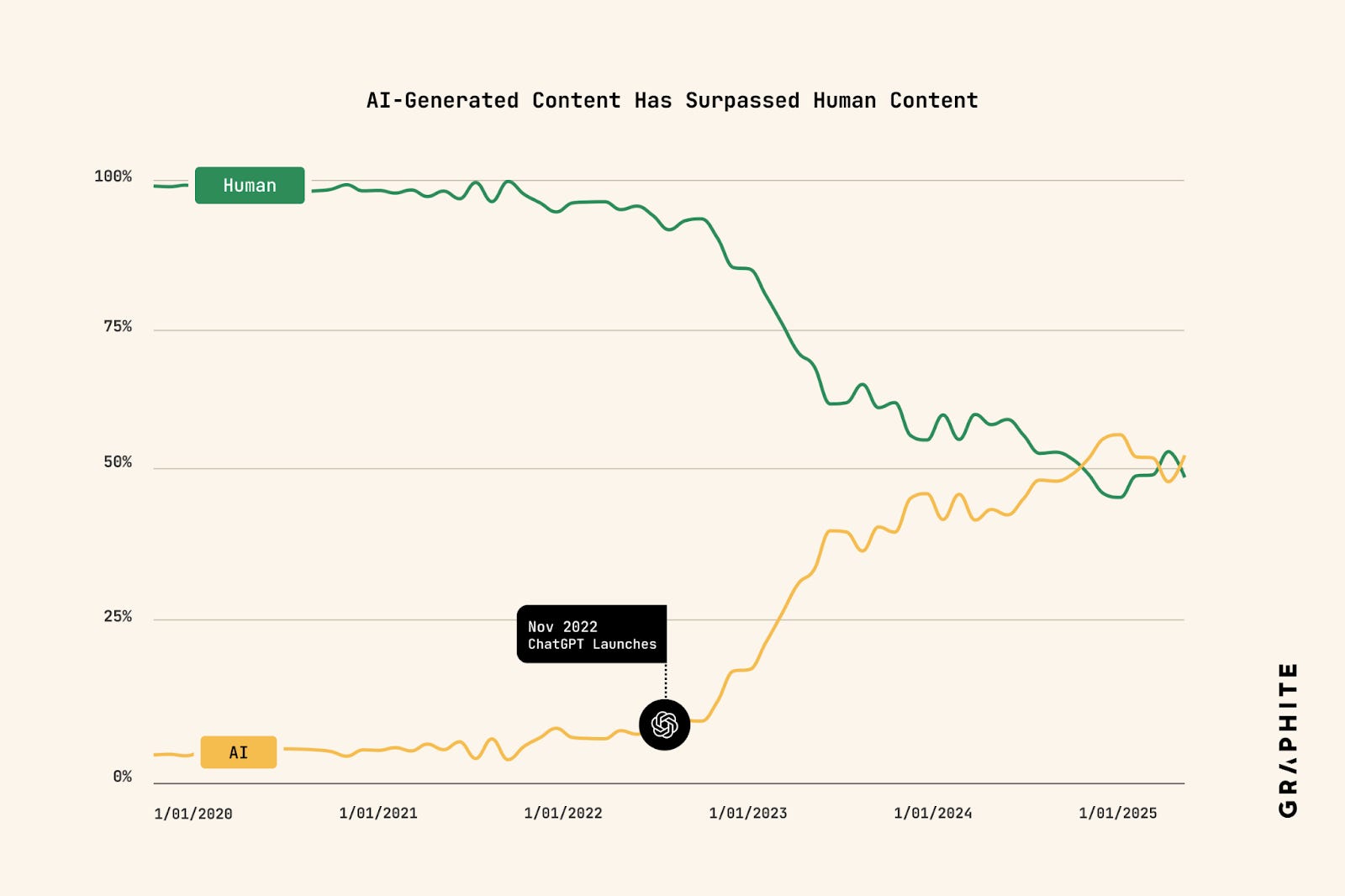
Now, the flood is all around us. A report from the SEO research company Graphite estimated that as of earlier this year, more than half of all articles online were created by generative AI tools, beating out those created by humans. Users of platforms such as X and Instagram do not need me to tell you that there has been a burst in AI bot accounts or AI influencers and actresses such as Tilly Norwood.
The result, as predicted, is what I called the “infinite Times Square,” where any area not locked off is a mix of real and not real, aggressively competing for attention and trying to seem “authentic.” We see this in everything from bots to an Italian philosopher named Andrea Colamedici writing a book about the dangers of AI “Hypnocracy” with the help of AI and then releasing it under the pseudonym of a fake Chinese academic.
Dangers from this have included the ones that I mentioned five years ago, with some calling the flood of AI slop as an example of “enshittification”, some looking at its impact on misinformation and disinformation and recent research suggesting that smaller publishers and creators are like small islands going underwater as a narrow group of larger outlets are disproportionately cited in AI answers.
This is where I thought, and still think, that new forms of data, like those Overtone was built around, are key to making the internet more human again. The previous essay was a jumping off point for the founding of the company and we now offer content understanding data for everything from the level of journalistic depth, the type of article, the concepts mentioned, the emotional tones, potential misinformation signals and more.
All of this can be combined into customisable models our clients use to better understand the internet around them and find the most relevant articles (as well as audio and now images) to support. The first step in dealing with a flooded landscape is to have a map. Solid data is that map.
Solipsism, communities and ChatGPT with ads
But now that the flood is here, we can see worries beyond the paradigm of what we cared about as issues five years ago, ones that emerge when technologies are widely used.
One of the changes seeing widespread adoption for the first time is mass personalization of content, through mechanisms like chat interface responses. Levels of personalization have existed before, through algorithmic recommendations on social platforms, for example.
However, the particularity of chat responses, coupled with the mixture of real and unreal seen in episodes like the Colamedici example, leads to something else. Alienation from an external world that you cannot understand as real or not real can lead to an isolation so profound that it is akin to solipsism, or a skepticism about everything in the external world beyond your own self, a la the brain in a vat scenario. One of the more disturbing threads around ChatGPT specifically in recent months has been its connection to suicide.
The current and future levels of personalization differ from algorithmic recommendation on Facebook, for example, because of the memory and specificity of the experience but also the sheer size of content when used at scale on a societal level. One of the dangers is not just the chatbot responses themselves but because the information ecosystem now has so much content, the percentage of all that content that one individual can see is getting smaller and smaller.
These low percentages mean that the percentage of content you’ve viewed and that someone else also has, so that you can talk and discuss it in your communities, will decrease and decrease. The information ecosystem will become further and further fragmented so that we are all essentially islands.
This fragmentation is on the verge of being deeply enmeshed with the way that the internet is funded, as OpenAI has been actively recruiting for advertising-focused roles for a while and CEO Sam Altman has said he is not against adding ads to the platform.
But supporting the hyper-fragmentation of our information environment with advertising budgets is not good for the information environment or advertisers themselves.
Over the last five years, Overtone has worked with actors all over the information ecosystem, from publishers to advertisers, and the thread that unites the good actors, and differentiates them from the bad actors in every category is a focus and care for the communities they serve and work with.
That is why Overtone has seized on the idea of “cultural moments”, using our models to understand what tones, types and topics make a community tick and following them through time as different events pique their interest and bring them together in discussion, rather than trying to gobble up all the possible personal data such as whether an individual bought a toilet seat last week. Brands that want to reach their audiences can be there with the communities they serve, essentially sponsoring moments online the same way they sponsor in-life events, finding places in the flood where people have gathered together for something real.
Going forward
I increasingly believe that moments, real-time discussions accessible to all without control by a centralized algorithm distributing them, should be the basis for how the internet operates and is funded. Data about moments and the content that make them up is essential here as well, and can serve as a common standard of the characteristics of different moments so that they can be understood at a glance.
Data about content can function not only as a map, but a passport, a face to meet the faces that an article meets as it is read online and becomes part of larger cultural waves. This is scalable from angry outbursts about political corruption in your local town to global outpourings of praise from wildly different corners for Rosalía’s new album (very much having a moment).
As the future of journalism is reimagined by thinkers such as David Caswell, I believe that the right data can also help serve the underlying mission and purpose of helping everyone online understand the world around them at scale and in the granular detail of linguistic nuance down to the paragraph level.
Looking forward to the next five years of artificial intelligence, I see that our current moment is still very much focused on trying to get AI to accelerate and optimize processes that have existed before, with questionable results. But the biggest opportunity to use AI for good isn’t in streamlining the same flawed systems that we had before, but in achieving things that would never have been possible without it.
There is an internet waiting to be born that understands the humanity and creativity of culture in real-time and can connect users in communities without control by a centralized algorithm. Building artificial intelligence systems to help create the data that powers these systems and enable larger scale understanding of nuance remains the best use case for AI.